
Decoupling Storage from Query in AWS Data Warehouses
April 15, 2026When building data warehouses on AWS, it is common to query tables directly through Athena. This works well initially, but over time it creates a tight coupling between storage and consumption.
Changes to the underlying data — whether it is a migration to a different storage system, a schema change, or a restructuring of tables — tend to propagate directly to dashboards and downstream queries. What starts as a convenient setup gradually turns into an implicit contract that is difficult to change.
This article describes a simple pattern to address this: introducing a contract layer using views. By treating the query layer as a stable interface, it becomes possible to evolve the underlying storage without breaking consumers.
The Problem: Storage and Queries Are Tightly Coupled
In AWS data warehouse projects, I keep seeing two recurring situations that create the same underlying problem: consumers end up tightly coupled to the storage implementation.
The first is the classic “on-prem database to S3 + QuickSight” migration. Teams start by exposing source tables and querying them directly—often through Athena—because it’s the fastest way to get to “we have dashboards.” But as soon as the underlying storage changes (new table layout on S3, different database, different naming, different ingestion approach), the coupling shows up immediately: dashboards break because table names or structures changed. Even worse, the migration becomes tedious because every dataset in QuickSight needs to be updated to point at the new tables. Instead of evolving the backend incrementally, you’re pushed toward a big-bang cutover—not because it’s a better plan — but because too many consumers are implicitly bound to the old implementation.
The second situation is plain schema drift. Somebody adds columns (“we need one more field”), or removes columns (“we don’t need that anymore”) in the underlying table. If consumers query those tables directly, even small changes can ripple out into downstream queries and dashboards. In practice, this becomes a reliability problem: the storage layer isn’t just an implementation detail anymore—it has accidentally become your public API.
The uncomfortable conclusion is that querying tables directly turns internal decisions into external contracts.
In practice, it often looks like this:
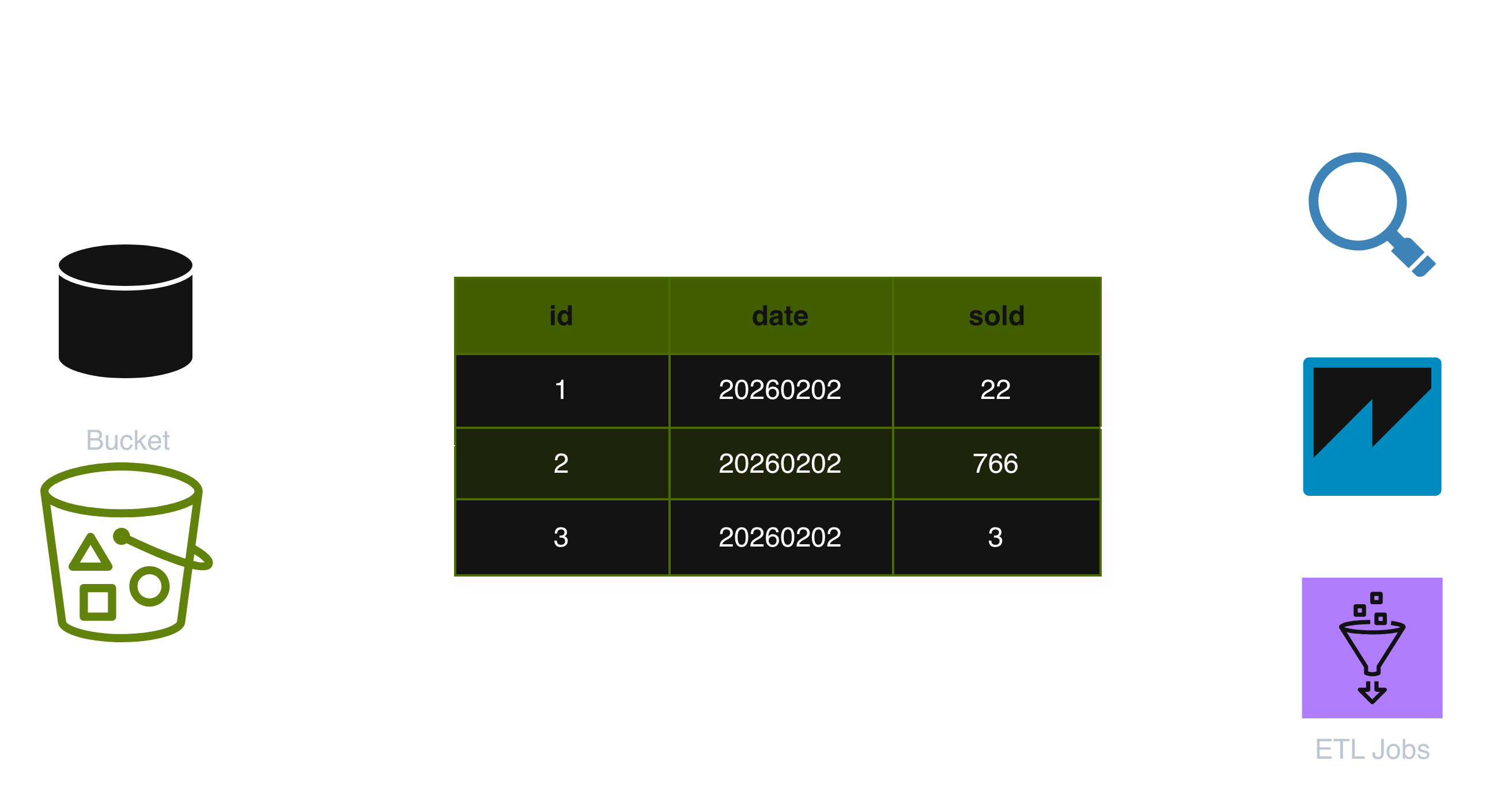
In this case, when the schema changes, all respective consumers break:
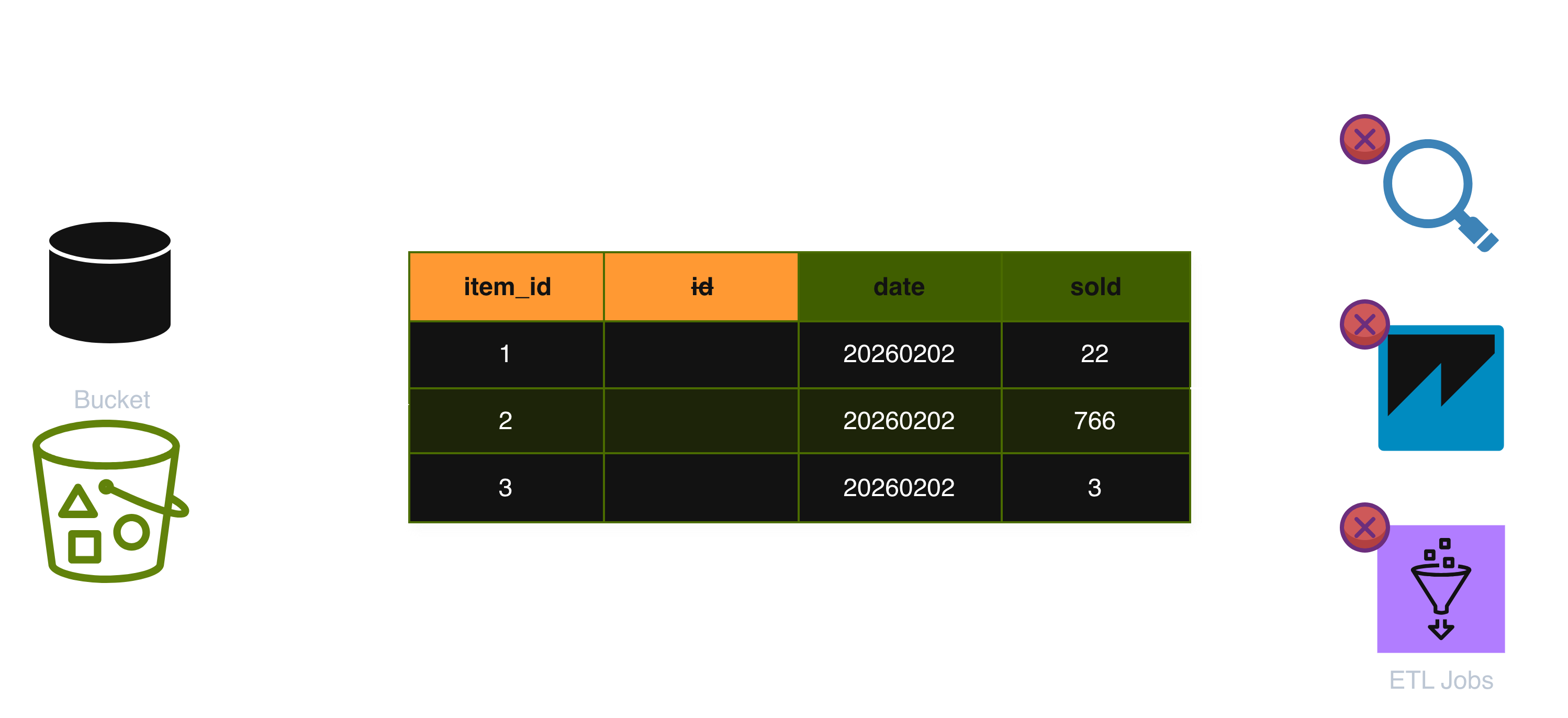
This is what makes migrations and schema evolution unnecessarily painful, especially for business users. They should be able to build datasets without needing to understand where the data lives or how it’s stored.
The Core Idea: Introduce a Contract Layer
The solution is simple: introduce a contract layer between consumers and storage.
In practice, this comes down to a simple rule: every table that should be consumed is exposed through a view, and consumers query the view instead of the underlying table.
Concretely, this introduces a stable interface between storage and consumers:
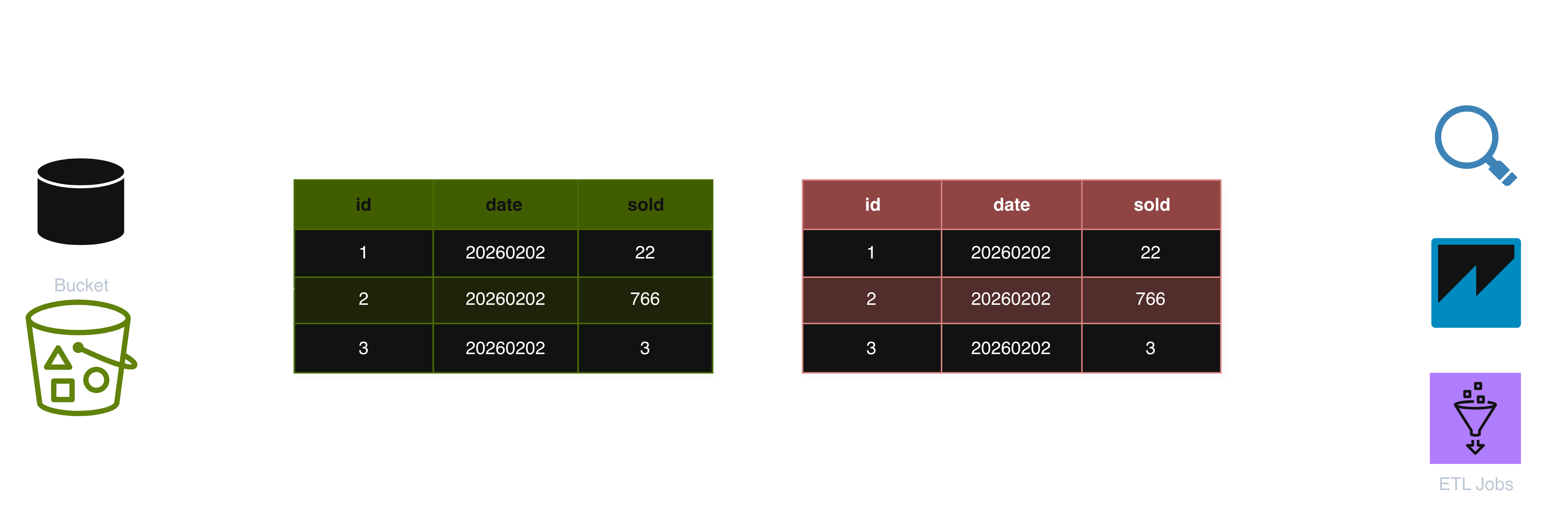
To make this boundary explicit, I recommend creating a separate Glue database that contains only these views. This database becomes the public interface of the data warehouse. Downstream tools such as QuickSight can then be configured to only access this database, and datasets are created exclusively from the views it contains.
A minimal example looks like this:
CREATE VIEW dwh.orders AS
SELECT
id,
date,
sold
FROM raw.orders;
Consumers then query the view instead of the underlying table:
SELECT *
FROM dwh.orders;
With a contract layer in place, the same change looks like this:
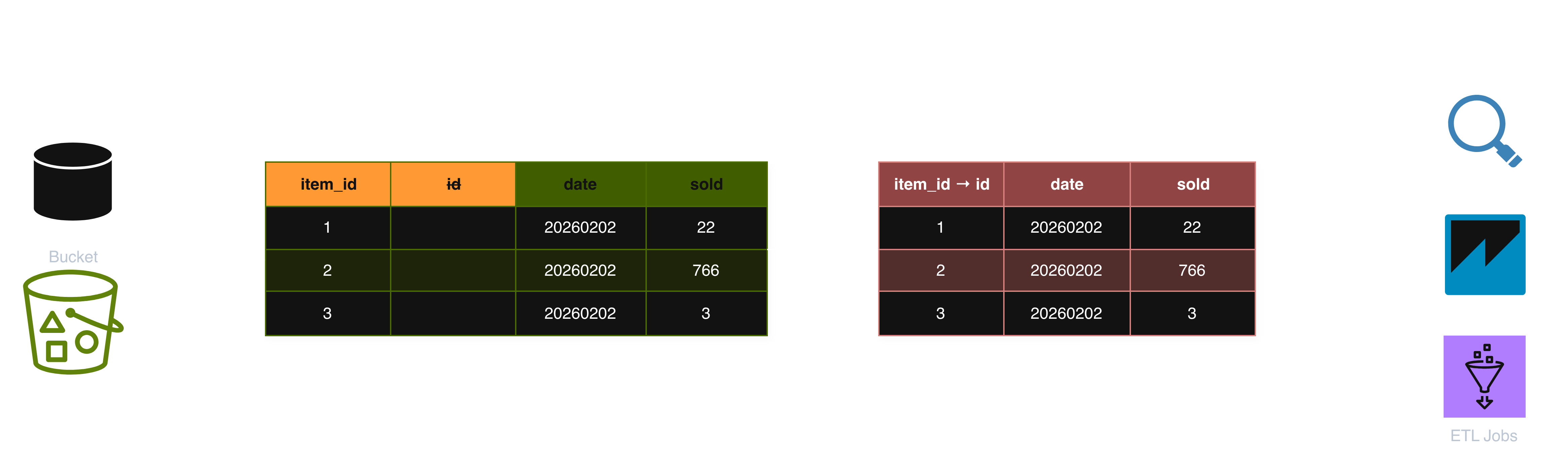
Only the view definition needs to change:
CREATE VIEW dwh.orders AS
SELECT
item_id as id,
date,
sold
FROM raw.orders;
From a software engineering perspective, this layer can be thought of as the public ABI of the data warehouse. The view defines the interface that downstream systems depend on: column names, types, and semantics.
The term ABI (Application Binary Interface) comes from systems programming. It describes the contract that compiled programs rely on when interacting with a library. As long as the ABI remains stable, the implementation behind it can change without requiring consumers to be rebuilt. The same idea applies here: as long as the view remains stable, the underlying storage can evolve without breaking downstream queries.
Keeping this contract layer in a separate Glue database also avoids coupling it to a specific storage system. For example, when using Athena federation to query PostgreSQL, the Glue database representing the source corresponds to the actual PostgreSQL schema. Creating views there could result in objects being created in the source database itself, which is usually not the desired outcome. By placing the contract layer in its own database, the interface is completely decoupled from the underlying storage systems.
What This Enables
Introducing a contract layer has different advantages depending on who you talk to.
For organizations currently migrating systems, the main benefit is flexibility. If consumers only depend on views, the underlying storage can be replaced without breaking dashboards or downstream queries. A table that is initially sourced from a federated database can later be replaced by a table stored in S3, Iceberg, or any other storage backend supported by Athena. As long as the view remains stable, the change is transparent to consumers.
For teams that frequently evolve their schemas, the contract layer provides a degree of stability. Views can expose only the columns that are part of the contract, so adding new columns to the underlying table does not affect existing queries. Even certain breaking changes can be handled at the view level by providing default values or compatibility mappings.
Data engineers often appreciate a different aspect of the pattern. They usually have the skills to update queries when something changes, but they would prefer not to spend their time fixing dashboards or explaining schema changes to downstream users. Keeping a stable contract layer makes migrations easier to perform incrementally and reduces the likelihood of complaints from consumers.
Analysts tend to benefit in another way entirely: reduced complexity. In many cases the physical storage details of a dataset are irrelevant to them. Whether the data ultimately comes from Oracle, PostgreSQL, S3, or DynamoDB does not help them build a dashboard about January’s revenue by product category. The contract layer allows irrelevant technical details to be hidden so analysts can focus on the data itself instead of the infrastructure behind it.
Depending on the audience, the contract views can also be used to simplify the exposed schema. Technical columns such as ingestion metadata or pipeline identifiers can be omitted if they are not useful to analysts. At the same time, the same mechanism can be used to handle sensitive data. Different views can expose different subsets of a table, and access to those views can be controlled through Lake Formation permissions when using Glue Data Catalog views.
Implementing the Contract Layer in AWS
In Athena you will encounter two kinds of views in practice: regular Athena views and Glue Data Catalog views.
Both are stored in the Glue Data Catalog and can be queried through Athena. The difference lies in their capabilities and how they integrate with other AWS services, especially Lake Formation. Glue Data Catalog views are created using the CREATE PROTECTED MULTI DIALECT VIEW ... SECURITY DEFINER syntax and are designed to work with Lake Formation’s permission model. In the remainder of this article I will simply refer to them as Glue views.
If a client plans to use Lake Formation for governance and access control, I generally recommend starting with Glue views right away. They allow the contract layer to act as an actual security boundary: consumers can be granted access to the view while the underlying tables remain inaccessible.
Even if security is only a vague future requirement, starting with Glue views can still be a sensible choice. They do not introduce meaningful additional cost. They are just metadata stored in the Glue Data Catalog, but they provide a clear path to introducing governance later without redesigning the contract layer.
If governance is not a concern, Athena views are often the simpler option. They behave very much like views in a traditional relational database, which makes them familiar to many database engineers and DBAs.
However, there are also differences between Athena views and Glue views. Athena views support a wider range of SQL constructs, while Glue views impose certain restrictions. This means that moving from Athena views to Glue views later can require adjustments to the view definitions.
One practical example is joins: Glue views can reference only a limited number of tables in a single definition. This is usually not a problem for the contract layer itself, but it can become relevant when people start building more complex views, for example when modeling star schemas with fact tables joined to multiple dimensions. Athena views do not have this restriction.
This asymmetry also affects migration strategies. Moving from Glue views to Athena views is straightforward because Athena can query Glue views. If necessary, you can simply create an Athena view on top of the existing Glue view. Moving from Athena views to Glue views, however, may require redesigning the contract layer if the existing view definitions rely on unsupported features.
Independently of the view type, I recommend a general rule for keeping the system manageable: avoid building multiple ABI layers on top of each other. Contract views should reference tables directly rather than other views. The main reason is maintainability. When something in a dashboard looks wrong, it should be possible to answer the question “which table does this ultimately come from?” by inspecting a single view definition instead of following a chain of transitive view references.
The same principle of not nesting ABI layers also applies to BI tooling. For example, QuickSight datasets can be built on top of other datasets, but doing so introduces additional indirection that makes systems harder to reason about and maintain.
A Typical Architecture
The exact structure of a data warehouse depends on the organization and its stakeholders. In practice, you will often see a layered approach, but not all layers are part of the data warehouse itself.
Raw data typically lives outside the warehouse, often in object storage such as S3. It may be unstructured or only loosely structured, and is primarily used as input for ingestion and transformation processes.
From there, ETL or ELT pipelines transform and move the data into more structured representations. Staging data is often kept in object storage as well, where it can be accessed for intermediate processing.
The actual data warehouse is usually represented by curated datasets, for example in systems like Redshift. These are the tables intended for analytical use and reporting.
With a contract layer in place, the architecture looks like this:
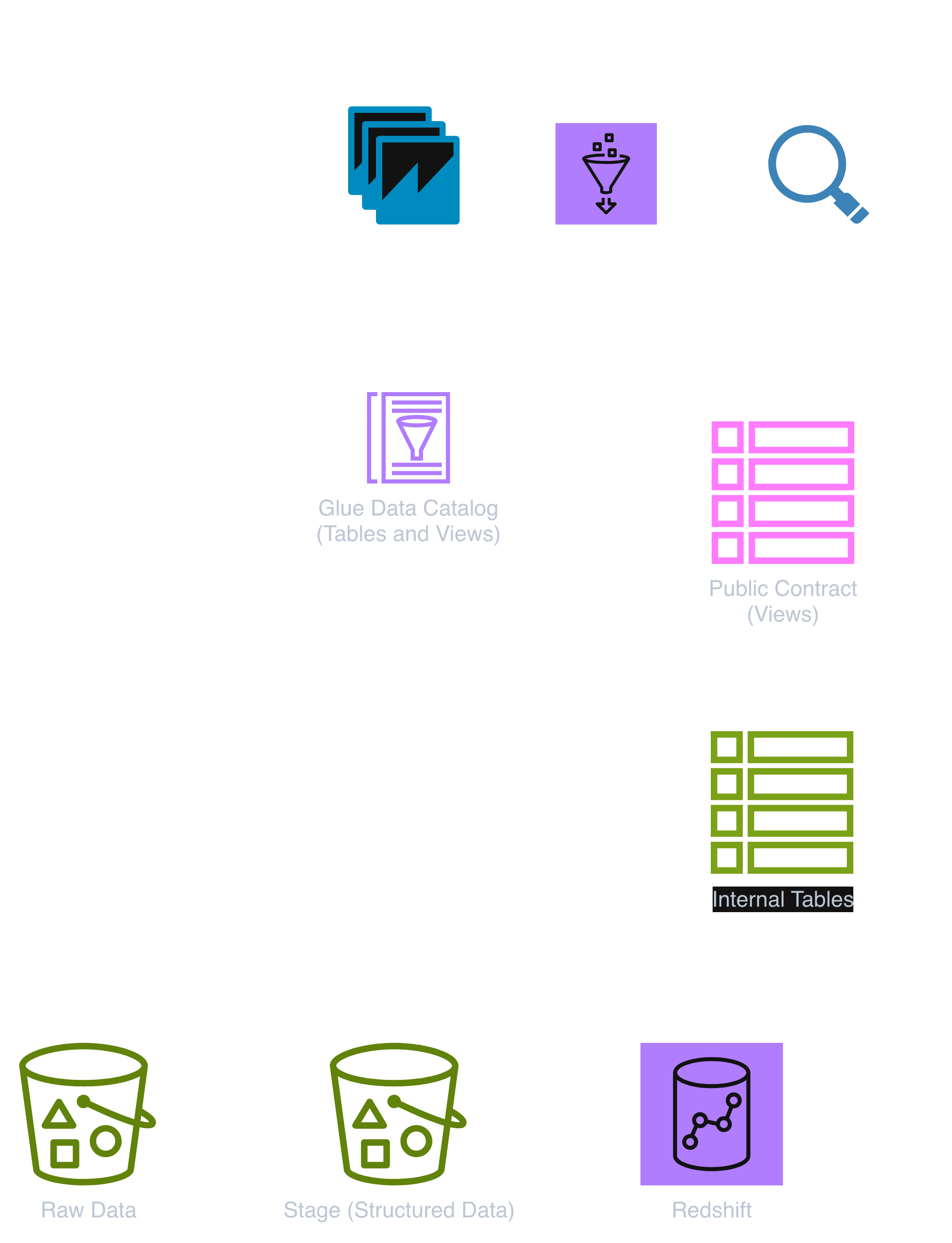
Producers manage their own datasets and expose them as internal tables. These tables are not intended to be consumed directly. Instead, they are exposed through views that define a stable, public contract.
Consumers — whether dashboards, data pipelines, or direct SQL queries — access only this contract layer. The underlying storage and table structure remain an internal implementation detail.
This effectively introduces a clear boundary between data production and data consumption. As long as the contract remains stable, the underlying implementation can evolve without breaking downstream systems.
Conclusion
Introducing a contract layer using views is a simple change in architecture, but it has a significant impact on how a data warehouse evolves over time.
By decoupling storage from queries, it becomes possible to change underlying systems, adapt schemas, and introduce governance without breaking downstream consumers. The views define a stable interface, while the tables remain an implementation detail.
The pattern does not remove the need for careful data modeling or migration planning, but it provides a clear boundary that makes these changes easier to manage.
A useful rule of thumb is to treat the query layer as a contract: if data is consumed, it should be exposed through a view. Keeping this interface stable allows the underlying system to change without affecting its users.

With over a decade of hands-on AWS experience and certifications spanning Developer to Security Specialty, Robert works as a Cloud Consultant at superluminar. Here, he shares stories and insights from his work — from serious AWS challenges to playful experiments and everything in between.