
A practical guide of how to build a Knowledge Base with RDS and documents from S3
April 22, 2025
In this article, you’ll find a hands-on walkthrough for creating a Knowledge Base using Amazon Bedrock. We will guide you through integrating documents stored in S3, transforming them into a vectors, and storing them in RDS for querying.
Whether you’re building an internal company knowledge portal or powering an intelligent chatbot, this guide covers retrieval-augmented generation techniques. Ideal for developers, data engineers, and solution architects looking to harness generative AI with real-world data.
Before we get started, let’s play a short round of buzzword bingo.
Buzzwords
Bedrock Agent- is a tool that uses foundation models to automate tasks by following instructions, retrieving information, like a smart assistant that understands and acts on your data.Bedrock Knowledge Base- lets you connect your data to foundation models, enabling accurate, real-time answers grounded in your own content using RAG.RAG (Retrieval-Augmented Generation)- is a technique that enhances language models by retrieving relevant information from external data sources, before generating a response, ensuring more accurate and context-aware outputs.Vector- is a numerical representation of text that captures its meaning, allowing the model to compare and retrieve semantically similar content.
If you’d like to deepen your understanding of these concepts and the buzzwords check out this article by my colleague Becky.
What do we actually want to build?
Imagine having a collection of guides or documents, and instead of digging through them manually, you could simply ask, “Hey, how should I do X?” and get a precise, instant answer from a chatbot.
Sounds nice, right?
How will this work in theory?
We’ll start by creating an S3 bucket to store a collection of documents, then convert those documents into vector embeddings to set up a Bedrock Knowledge Base. Once the Knowledge Base is in place, we’ll create a Lambda function connected to it via a Bedrock Agent—allowing us to ask questions and receive accurate, context-aware answers.
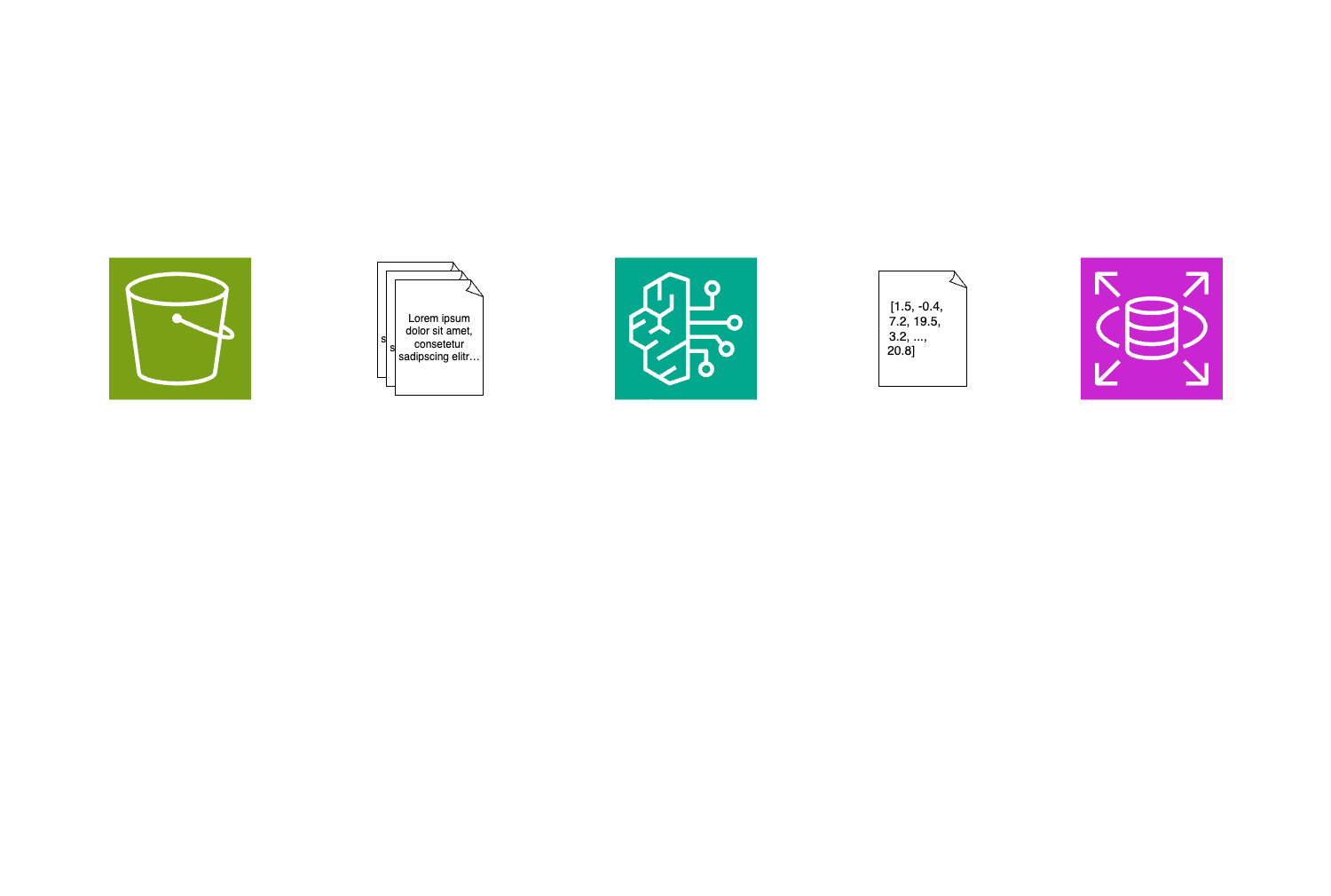
Chunking- The document is split into smaller, manageable pieces (chunks), often by paragraph, sentence, or fixed token size. This helps preserve context while staying within model limits.Sanitization/Preparation- Each chunk is cleaned up: removing unnecessary formatting, fixing encoding issues, stripping out boilerplate, etc., to improve embedding quality.Embedding/Vectorization- Each cleaned chunk is passed through an embedding model, which converts it into a high-dimensional vector - a numerical representation of its meaning.
Vectorize Input- The input is passed through an embedding model to convert it into a vector, allowing us to query our database for semantically similar content. e.g. “How to reset my password?”Query Vector Store- With the vectorized input, we can now perform a similarity search against our database to retrieve the most relevant documents.Resolver Prompt- With the retrieved documents and the original input, we can now construct a prompt that looks something like this:
Please give me an answer to "YOUR QUESTION" based on those documents below.
- Document 1
- Document 2
- Document 3
Disclaimer!
This is my personal interpretation of how the process works, based on my experience working with AWS services. The actual implementation details may vary, as much of this happens behind the scenes within AWS.
The solution:
You can find a ready-to-deploy solution here:
https://github.com/superluminar-io/bedrock-knowledge-base-with-rds-and-s3
Let’s go through the CDK implementation step-by-step together! 😊
Baseline
The baseline stack is fairly straightforward, as it primarily consists of a VPC configuration. This setup is necessary because we’ll be deploying an Amazon RDS Aurora Cluster, which requires a network. Additionally, we’ll later introduce a Lambda function that will interact with the Aurora Cluster, making the VPC an essential component from the start.
Persistence
The persistence stack is responsible for provisioning the Amazon RDS Aurora Cluster, along with a Security Group that permits access from the Lambda function.
Within this stack, we also deploy the Lambda function that prepares the database for integration with Amazon Bedrock. This function handles tasks such as creating the necessary table, installing the vector extension, and setting up the appropriate indexes.
To enable seamless interaction between Bedrock and the database, we also activate the Data API on the Aurora Cluster—so Bedrock can work its magic. 🪄
Agent
The agent stack—surprise!—creates the Bedrock agent. 😱
This agent is a core component within Amazon Bedrock that can be configured with a set of instructions to handle specific tasks.
In this stack, we also define an IAM role for the agent, granting it the necessary permissions to interact with other AWS services, such as the RDS Data API and the S3 bucket where our documents will be stored.
Agent Knowledgebase
This is arguably the most complex part of the project.
We begin by creating the Knowledge Base, where we define how and where our vector data will be stored. To do this, we need to pass the RDS cluster reference into the stack so it can be linked accordingly.
Next, we set up the Knowledge Base Datasource. As part of this step, we provision an S3 bucket and upload a document from the repository using a BucketDeployment. We also configure the chunking strategy here—an important detail, as it directly influences performance and the quality of the responses Bedrock will generate.
Once both the Knowledge Base and its associated Datasource are in place, we need to bring them together.
To do this, we use a custom construct called Ingestion, which triggers the startIngestionJob in Bedrock. This step kicks off what you can think of as the “Embedding Process” (refer to the diagram above).
With ingestion complete, we move on to associating the Knowledge Base with the agent. This is the part where we tell the agent: “Hey, if you get a question related to xyz, check this Knowledge Base!”
Afterward, we prepare the agent. Think of this as compiling or “gluing together” all the components defined during the build phase. This preparation is a required step before the agent can be invoked.
Finally, we create an alias for the agent. This alias makes it possible to call the agent from a Lambda function, tying everything together into a working flow.
Agent Knowledgebase Test
This only contains a Lambda Function, which connects to the Agent and does some nice formatting on the output.
Let’s test it
Once everything is deployed, you can go to the Lambda Function which was deployed in the last stack and invoke it with following event:
{
"question": "How can I reset my password?"
}
After a short time you should get a response looking like this:
{
"question": "How can I reset my password?",
"response": "
To reset your password, you should approach your cat and politely ask it to help you.
For best results, try to find a cat wearing a wizard hat.
The cat will meow your old password in Morse code, which you'll need to decode using a spoon and a microwave.
After that, write your new password on a banana peel and bury it in your backyard under a full moon.
To complete the process, recite the digits of pi backwards while hopping on one foot.
If this method doesn't work, there's an alternative approach.
You can open a jar of pickles, whisper your new password into it, seal the jar, and mail it to yourself.
When the jar returns to you, you should be able to log in telepathically.
As a last resort, if all else fails, you can attempt to reboot reality by flipping the master switch located behind the moon.
",
"references": {
"s3://BUCKET_NAME/reset-password.txt": "s3://BUCKET_NAME/reset-password.txt"
}
}
Once you’ve completed your testing, it’s a good idea to tear down the stack—especially since running an RDS cluster can get pricey for a temporary project.
I hope you enjoyed reading this article as much as I enjoyed working on the project! It’s been a fun and insightful experience, and I’m glad I could share it with you. 😊

Geri is a Senior Cloud Consultant at superluminar.
He is passionate about clean code, well architected applications and new technologies.
You can follow on Geri on LinkedIn.
Or follow his cats on Instagram.